
Lora模型训练
参考:
- https://www.bilibili.com/video/BV1m9xKeHEXh/?vd_source=b1de3fe38e887eb40fc55a5485724480
- https://www.bilibili.com/video/BV16e411e7Zx?spm_id_from=333.788.videopod.sections&vd_source=b1de3fe38e887eb40fc55a5485724480
准备篇
如果训练单一角色的lora,20~30张图片即可,如果要训练画风的lora,图片数量建议要更高一些,300张左右.

sd1.5的底模推荐选择:

素材的注意项
1.图片格式要统一
2.图片不要带有alpha通道,图片推荐jpg格式
3.图片大小在1024为基础
4.图片比例不要太夸张
图像预处理
裁剪
推荐提前将图片裁剪为预训练模型对应的图片分辨率,sd1.5为512×512,sdxl为1024×1024.对于不好裁剪的图片,可以开启分辨率桶来分开训练.
打标
越希望AI学习的东西,越不能出现在标注里.
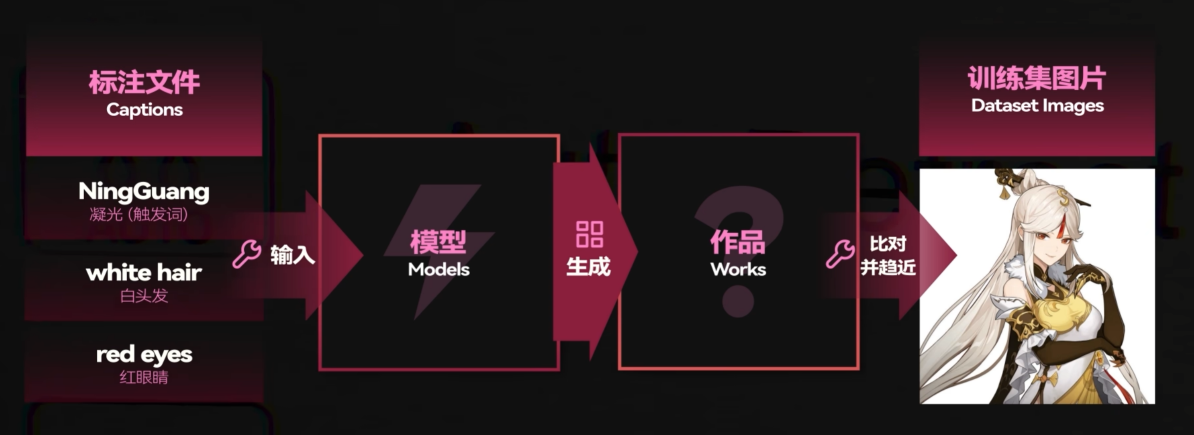
解释:首先回顾AI训练的原理:通过标注文件让底模生成的图片变得越来越像训练集的图片,最终得到lora模型来对底模进行微调,配合触发词即可生成想要的图片.在训练过程中触发词每次都会出现在标注中.
例如凝光角色lora这里的示例:如果除了触发词之外,打标都有white hair,red eyes的话,只有当触发词和white hair和red eyes一起配合的情况下才会出现凝光这个角色形象,而不是仅仅输入触发词就可以了.

标注清洗
可以通过Dataset Tag Editor来进行标注的清洗.
清洗过程:
- 整体审核: 首先需要将训练集的所有打标中对于明确不符合角色特质的错词进行删除,然后删除与训练对象本体识别特征密切相关的词(例如角色的发型,发色,头饰,眼睛颜色等),对于识别不正确的内容进行替换.
- 批量调整:一些共通,有明确特质,元素的图片,可以为其批量增加一些标签.这样能够防止lora模型将这些共同特征当成必要的.
- 单张修改:对于自动打标不好的图片,进行单独的修改.
参数
参数介绍
Repeat(训练次数):,重复学习训练集图片的次数,影响步数计算和学习效果,二次元图片推荐5~10,三次元图片推荐10~30.
Epoch(训练轮数):AI训练一轮之后(过完了训练集的每张图片),还需要重复训练的轮数.
Enforce number of steps(最大训练步数):训练集的规模在20~30张的话,1200~1500是不错的选择,
train_batch_Size(批量大小):同一时间同时训练的图片数量,值越大,训练的总时间越短.批量大小增加也会减少训练步数.当增加batch_size后需要同步的提高U-Net学习率
save_every_n_epochs:每进行多少轮数后自动保存一次模型.假如训练10轮,这个值为2,那么会输出5个模型
学习率:AI的学习强度.训练集图片增加的情况下,应该尝试降低学习率.训练样本的增加可能导致梯度下降算法在更新模型参数时需要更小的步长,因为更多的数据可能意味着更复杂的损失曲面。如果学习率过大,可能会导致训练不稳定或者错过收敛点。因此,一般会采取降低学习率的措施,或者开始就使用一个较低的学习率,逐渐增加直到能找到一个表现得更好的学习率数值。
Unet_lr(U-Net学习率):如果填上了U-Net学习率的参数,它就会覆盖学习率的参数,如果u-net训练过度,会导致面部扭曲或者产生大量色块,
Text_encoder_lr(文本编码器学习率):简称te,通常为U-net学习率的二分之一到十分之一,te训练不足会让出图对提示词的服从性更低,训练过度则会容易生成多余的物品.
Lr_scheduler(学习率调度器设置):在训练过程中动态调整学习率的机制,一般学习率调度器会在学习过程中慢慢降低学习强度的(防止过拟合).不同调度器对于最终训练效果差距不大.
Lr_warmup_steps(学习率预热步数):建议填总步数的5%~10%
Optimizer_type(优化器设置):决定了AI在训练的过程中如何把控学习的方式,常用的为AdamW8bit(当batch_size为1时推荐学习率1e-4,为2时推荐学习率2e-4,以此类推),Lion(推荐学习率7e-5,作者推荐当批次大小大于64时使用),Prodigy(又称神童,完全自适应的改变学习率,因此如果使用此优化器,学习率都直接设置为1即可)
Network_dim(网络维度):此参数越大,学习的就越深,最终lora模型就越大.数值推荐说法一:在训练三次元物体,形象或者复杂的画风时,推荐使用128或者64的高维度值,训练二次元画风或者人物时,通常使用32或者16或者8.数值推荐说法二: 训练集图片数量小于100时推荐32,100~500时推荐64,大于500时推荐128
Network_alpha:设置为与网络维度一样,或者为网络维度的一半即可.
Bucket Resolution(分辨率桶): 虽然训练集的图片建议都裁剪为512×512或者1024×1024,但可以通过开启分辨率桶来将训练集的图片分成自定义比例来分开训练.,关闭可以节约显存.
gradient_checkpointing(梯度检查点): 开启梯度检查点可以以时间换内存,开启后可以支持更高的batch_size,当batch_size为1时需要关闭,因为梯度检查点会降低训练速度.
gradient_accumulation_steps(梯度累积步数): 用于在小显存模拟大batch_size的效果,如果显存足够使用4以上的batch size就没必要启用。要求数值为2的n次方,如果批量大小是2,累加步数是32,那么就相当于批量大小为64,使用lion学习器,要求高批次大小,就必须开,如果不用lion就没必要开
caption_tag_dropout_rate(按逗号分隔的标签来随机丢弃tag的概率): 当使用dreambooth+标签的训练方法来训练画风,推荐使用这个参数,数值调整为0.2~0.5,能够防止过拟合.
clip_skip(clip跳过层数):当训练底模是基于sd1.5的模型时使用1,当训练底模是基于novelai的二次元模型时使用2,当训练sd2.0以后都使用2.
sdpa:优化与加速Transformer模型中注意力机制的计算,优化计算效率,加速gpu.
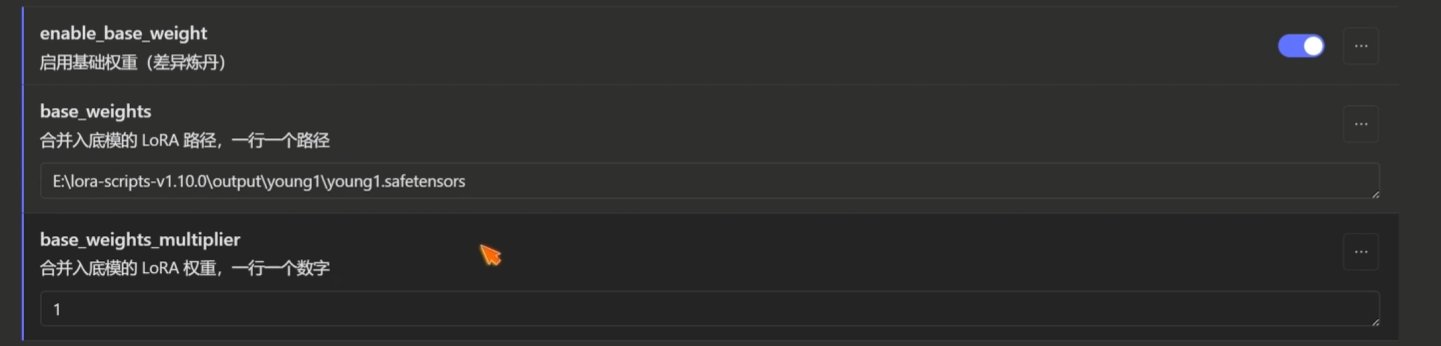
enable_base_weight(启用基础权重):用于差异炼丹,可以训练功能性lora,例如增减衣物lora,增加细节lora
如何针对训练结果进行训练参数的调整

判断lora模型的训练结果
一些词汇的介绍与如何判断样图不正常的原因
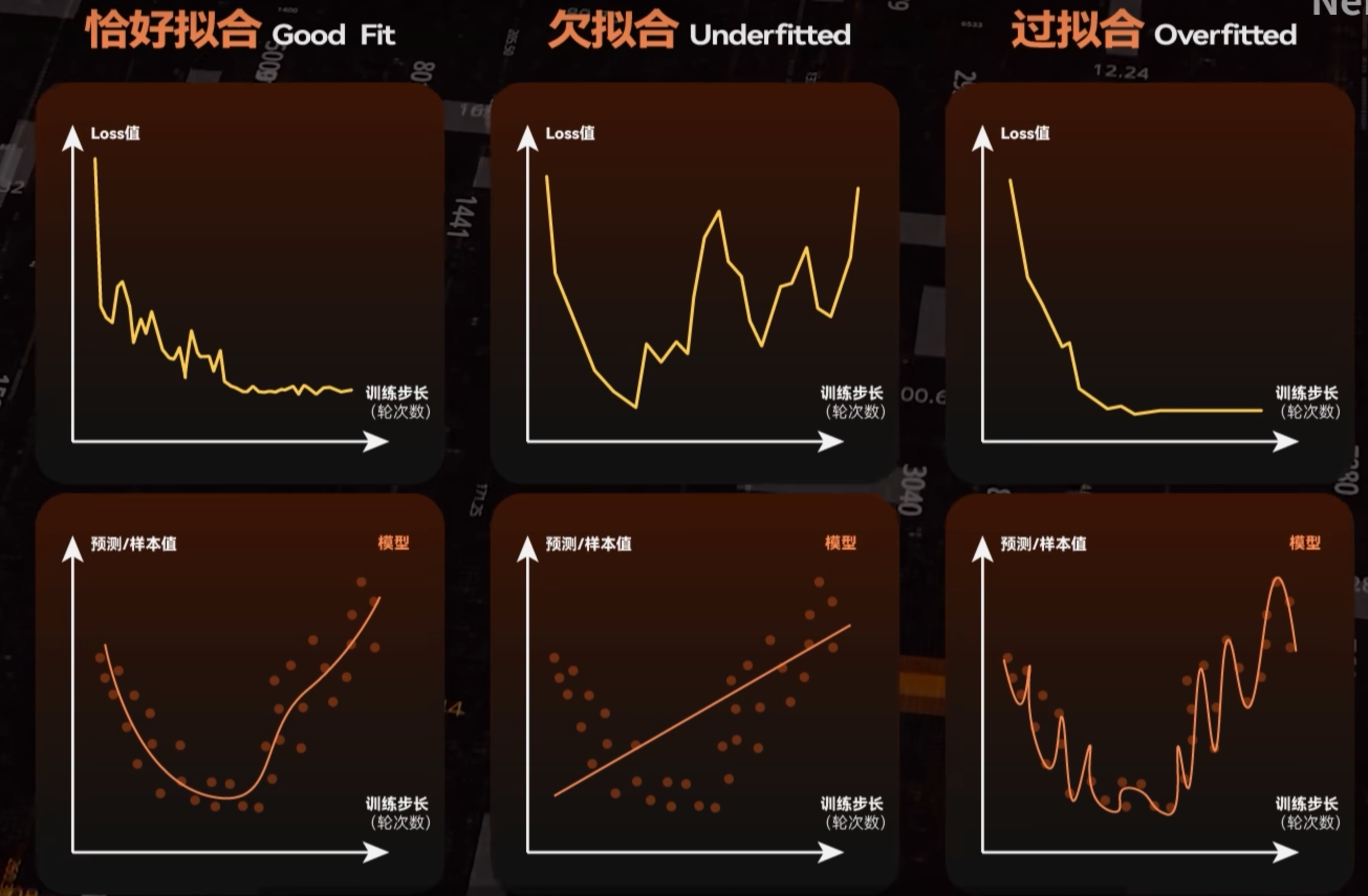
- 样图过拟合:生成的图片过分接近训练集的图片,并且发生了明显的画风畸变(面部扭曲,颜色异常,完全不像底模跑出来的风格)
- 样图欠拟合:生成的图片根本不像训练集的图片,用lora跟没用一样
- 样图十分的混乱,但能看出来学习的痕迹:维度设置错误(通常是过高)
- 样图模糊甚至黑图:炸炉了,需要重练.
loss值
loss是机器学习里用于判断神经网络学习情况的一个重要指标,loss值越低,说明拟合程度越高.
sd1.5推荐loss值小于0.1
flux推荐loss值在0.25附近
lora分层与融合
https://www.bilibili.com/video/BV1qM4y1j7tD/?vd_source=b1de3fe38e887eb40fc55a5485724480
正则化Lora训练
- 什么是正则化: 指通过添加额外的约束和惩罚项来改进学习算法的表现.以减少过度的拟合问题,能提高模型的泛化能力.
- 正则化数据集: 正则化图片和应当数据集有某些共通之处,但在期望降低权重的部分有所不同,图片数量一般多于训练集.
- 正则化训练操作: 正常训练模型的操作的基础上在正则数据集中添加图片即可.
- 训练速度的区别: 无论正则化数据集中放了多少图片,训练步数都会乘以2,训练时间都会翻倍.
- 训练画风时,画风也会受到正则化数据集的影响,所以正则化数据集不要放太多和画风差异太大的图片.
画风Lora训练
- 可以先使用sd1.5进行训练,因为它的速度最快,然后再尝试sdxl或flux版本.
- 收集画风lora数据集
- 打标,正常描述图片内容即可
- 测试如果风格可以,但是出图效果不行,可以通过更改底模为对应风格的底模(非融合模型)来进行训练
- 判断模型是否欠拟合,如果欠拟合可以增加轮数或者重复次数
- 根据效果优化参数,打标,数据集等
差异炼丹法(训练功能性lora)
增减衣物lora,增加细节lora,这些控制单一变量的功能性lora本质上都是通过向量相减,提取差异特征,使生成的lora模型不受原本大模型中画风和概念的污染.
差异炼丹法可以归纳为4种,分别是复印炼丹法,基于基础权重的差异炼丹法,基于SVD提取的差异炼丹法,滑块炼丹法.这四种方法都需要准备两组图片(原始图片和处理后的图片).这两组图片存在的差异就是我们要提取制作的lora.
步骤:
- 准备两组图片,放到不同文件夹,原始图片和功能应用后的图片
- 给每组图片进行提示词标记,要求不同组的处理前后的图片的提示词相同,提示词只需要任意描述加个序号即可(例如假如要做个变老的功能lora,那么就第一张图片就bianlao1第二张图片就bianlao2).不需要描述图片内容.
- 训练一个过拟合的lora(训练轮数乘以训练次数超过1000可以保证过拟合)
- 在训练参数保持不变的前提下,开启enable_base_weight(启用基础权重(差异炼丹)),然后填入刚才过拟合的lora路径进行训练.

提醒: - 数据集的选择: 4~8张即可.
- 应用场景: 操控体型,年龄,长度等变量
.jpg?raw=true)
.jpg?raw=true)
.jpg?raw=true)